阿里云人工智能 高级工程师 ACP
阿里云PAI(Platform of Artificial Intelligence
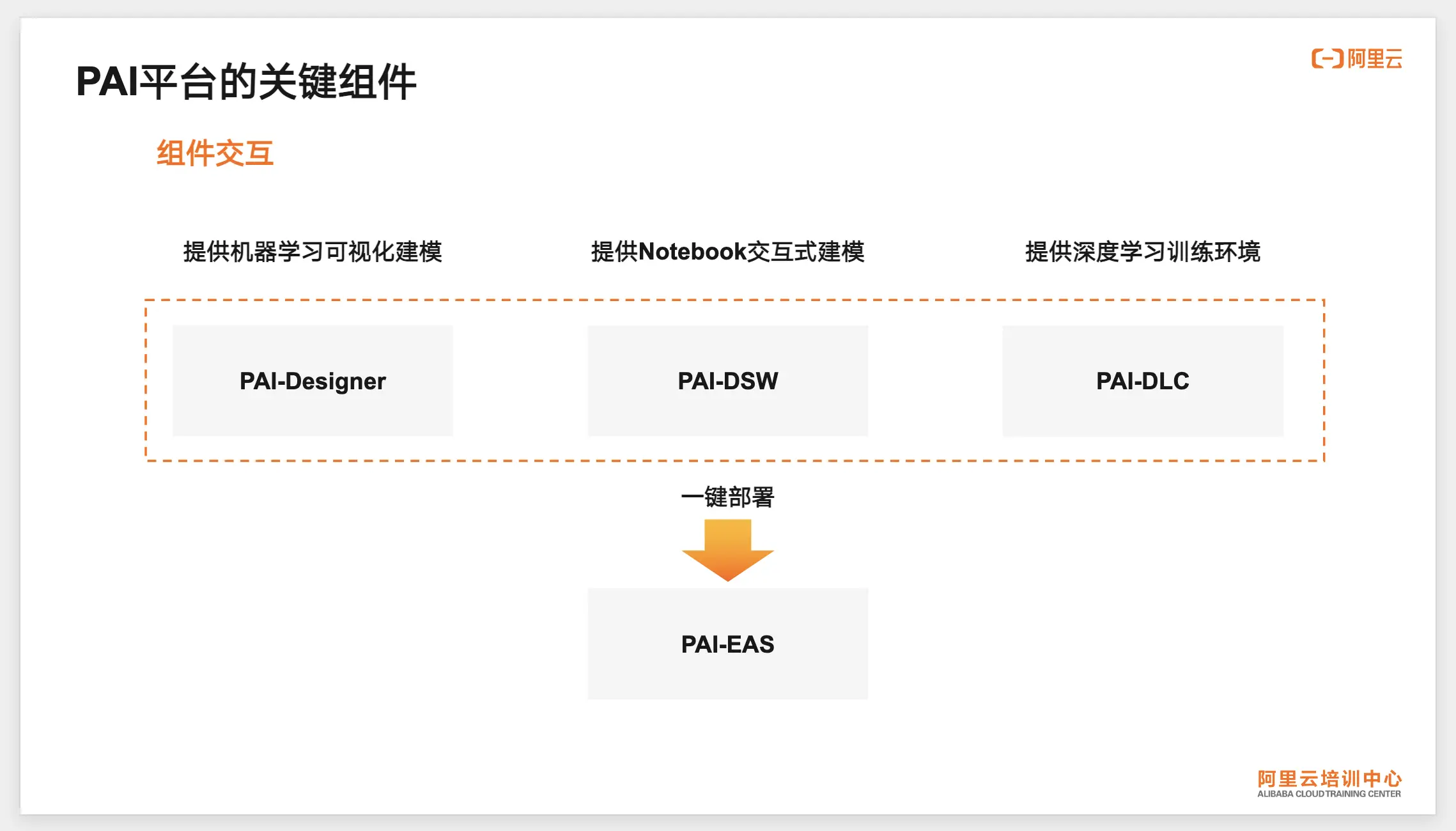
PAI-Studio:
- 可视化建模工具:提供了一个可视化的界面,用户可以通过拖拽组件来构建机器学习流水线,无需编写代码即可完成数据预处理、模型训练和评估等任务。
- 适合于希望快速搭建模型但不想深入编程细节的数据科学家和分析师。
PAI-DLC (Distributed Learning Cluster):
- 分布式训练框架:用于大规模并行化训练深度学习模型,支持TensorFlow、PyTorch等主流深度学习框架。
- 提供了高性能的计算资源管理和调度能力,可以显著缩短大型模型的训练时间。
PAI-EAS (Elastic Algorithm Service):
- 模型在线服务:帮助用户将训练好的模型轻松部署为RESTful API服务,使得模型可以直接集成到应用程序中进行实时预测。
- 支持弹性伸缩,能够根据流量自动调整实例数量,确保服务的稳定性和高效性。
PAI-AutoLearning:
- 自动化机器学习服务:通过自动搜索最佳算法和超参数配置,降低模型开发门槛,提高效率。
- 特别适用于没有深厚机器学习背景的技术人员,或需要快速迭代实验的场景。
PAI-DSW (Data Science Workshop):
- 交互式开发环境:提供Jupyter Notebook形式的在线工作区,方便开发者编写和调试代码,同时集成了丰富的机器学习库和工具。
- 支持多种编程语言,如Python、R等,是进行探索性数据分析和原型开发的理想选择。
PAI 存储
OSS (Object Storage Service):
作用:对象存储服务提供了海量、安全、低成本、高可靠的云端存储解决方案,适合存储非结构化数据如图片、视频、日志文件等。
对应服务:几乎所有的PAI服务都可以与OSS集成,特别是用于数据输入输出、模型保存和加载。例如,在PAI-Studio中可以配置OSS作为数据源或目标;在PAI-EAS中,模型可以从OSS加载。
MaxCompute:
作用:这是阿里云提供的大数据处理平台,支持批量处理和交互式分析海量数据,非常适合用于大规模数据集的预处理和特征工程。用于存储结构化数据
对应服务:经常与PAI-Studio结合使用,用于准备和清洗用于训练的数据集;也可以通过SQL接口进行数据探索。
NAS (Network Attached Storage):
作用:网络附加存储为用户提供了一个高性能的文件系统,支持多个计算节点同时访问共享文件系统,非常适合需要频繁读写文件的场景,如分布式训练。
对应服务:主要用于PAI-DLC(Distributed Learning Cluster),因为它支持跨多台机器的并行文件访问,对于深度学习框架如TensorFlow、PyTorch来说非常重要。PAI-DSW 扩容也是使用 NAS
速记
操作
对上传的数据集
导出、编辑、复制、删除4种操作。
对标注任务
标注、下线、导出、质检、编辑、复制、删除
对模型
测试、查看和下线三种操作。
PAI 自动建模场景
- 推荐召回
- 图片分类
阿里云人脸识别能够提供的能力
- 人脸美型
- 五官编辑
- 口罩人脸比对
迁移学习类型
基于样本、基于特征、基于模型
NLP 基础技术
词法分析、句法分析、语义分析
NLP 核心技术
机器翻译、智能问答、文本分类、情感分析、文本生成、自动摘要
智能语音交互创建项目
需要添加项目名称,项目类型以及项目的场景描述
PAI-EAS Processor 主要功能
- 将PMML类型的模型文件加载为一个服务
- 处理对模型服务进行调用的请求
- 根据模型计算请求结果,并将其返回至客户端
PAI-TF 调用方式
可以使用 PAI-Studio、MaxCompute Console 以及 Dataworks 的开发节点调用 PAI-TF
PAI-DSW 上传数据到 OSS 的方式
ossbrowser、ossutil、ossftp
增强学习中各个概念的定义
- 智能体(Agent):智能体是指在增强学习中执行决策的实体,它可以是一个机器人、一个智能设备或一个人类。智能体的目标是通过与环境交互来学习如何做出最优决策。
- 环境(Environment):环境是指智能体所处的外部环境,它可以是一个物理世界、一个虚拟世界或一个模拟世界。环境可以提供智能体观察到的状态信息,以及智能体执行动作后会获得的奖励信息。
- 策略(Policy):策略是指智能体在环境中采取的决策策略。策略可以是确定性策略(Deterministic Policy),也可以是随机性策略(Stochastic Policy)。确定性策略是指智能体在每个状态下都有一个确定的动作;随机性策略是指智能体在每个状态下都有一个概率分布,用于决定采取哪个动作。
- 动作(Action):动作是指智能体在环境中执行的操作。动作可以是一个离散的动作,也可以是一个连续的动作。
- 状态(State):状态是指环境中的当前状况。状态可以是一个离散的状态,也可以是一个连续的状态。
- 奖励(Reward):奖励是指智能体在执行动作后获得的反馈信息。奖励可以是一个标量值,也可以是一个向量值。
常见的离群值判别方法
四分位间距1.5(Q3-Q1)、随机森林、K-Means、标准差3σ
数据缺失分类
- 完全随机丢失:完全随机丢失是指数据缺失是完全随机的,与其他观测值没有关系
- 随机丢失:随机丢失是指数据缺失是随机的,与其他观测值存在某种关联
- 非随机丢失:数据的缺失依赖于不完全变量自身
- 无效丢失:在无效丢失中,丢失的数据是无效的,不能用于分析或预测
聚类算法分类
- 基于距离的划分
- 基于密度的划分
- 基于网格的划分
- 基于模型的划分
- 基于层次的划分
多元线性回归模型的条件
- 因变量和自变量之间具有线性关系
- 各个观察值都应该是相互独立
- 随机误差均值为零
- 随机误差方差相同且为有限值
集成学习
集成学习是通过选择不同的弱分类器,然后组成一个强分类器,达到一个有效避免过拟合的方法
自然语言处理中使用 CNN 实现的任务
语义分析、话题分类
自动摘要
将文本视为句子的线性序列,并且将句子视为词的线性序列
word2vec 的训练方法
- 连续词袋模型(CBOW)
- 跳字模型(Skip-gram)
文本的表示方法
词袋模型、word2vec、Glove、BOW、N-gram 等
常见构建决策树模型的算法
- 基于信息增益划分的 ID3 算法
- 基于信息增益比的 C4.5 算法
- 基于基尼指数划分的 CART 算法
阿里云自然语言处理 NLP 提供的子服务
- NLP 基础服务
- NLP 自学习平台
阿里云性能与支持参数
阿里云智能语音识别服务
包括录音文件识别、实时语音识别、一句话识别
录音文件识别
- 时长:不超过 30 分钟
- 大小:音频文件不超过 512 MB,视频文件不超过 2 GB
- 免费用户识别任务在 24 小时内完成,付费用户在 3 小时内完成
阿里云智能语音合成服务
SDK 接口: 安卓、iOS、JAVA、python、C++、C#、Go、Node.js
- 长文本语音合成:一次性最高 10 万字,每合成 5 万字,最快仅需 10 分钟
- 短文本语音合成:一次不能超过 300 字符。超过 300 字符的内容会被截断
阿里云自然语言处理
创建任务时项目名称和项目描述是必填项。
上传文件夹大小限制
200 MB
多语言分词支持语言
中文、英文、泰文、越南语
SDK 支持语言
JAVA、Python、C++、C#、PHP、Go、Node.js、Ruby
创建标注任务
任务名称、添加标注文件、添加标注人员
阿里云自然语言处理 NLP 子学习平台训练耗时一般为30分钟左右
阿里云自然语言处理 NLP 子学习平台训练模型评估指标
正确率、召回率、F1值
-
- 阿里云PAI(Platform of Artificial Intelligence
- PAI 存储
- 速记