图像生成模型
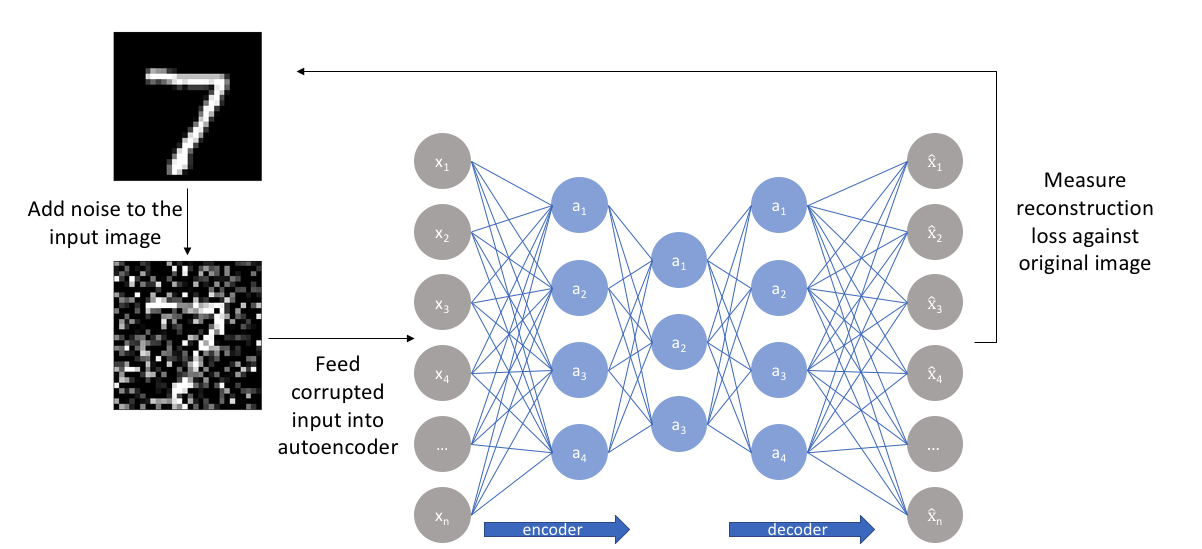
自编码网络 - AutoEncoder
自编码网络(Autoencoder)是一种神经网络模型,它的目的是学习原始数据的有效表示。它通过训练一个神经网络来学习一种从高维数据到低维表示的映射,从而达到降维的目的。这个映射的学习过程通常通过最小化输入和输出之间的差异来完成。
自编码网络的结构由两个部分组成:编码器和解码器。编码器将高维数据映射到低维空间,解码器将低维表示还原为高维数据。训练过程中,通过不断地调整网络参数来优化这个映射,使得输入和输出之间的差异最小。自编码网络也可以用于数据去噪和特征提取。
自编码网络类别
稀疏自编码网络
稀疏自编码器的隐藏层神经元大于输入层神经元。通过 L1、L2 或 Dropout 给隐藏神经元加入稀疏性限制。
降噪自编码网络
以一定概率分布去擦除原始输入矩阵,网络即会学习这种破损的数据,优点为:
- 破损数据训练出来的 weight 噪声比较小
- 破损数据一定程度上减轻了训练数据与测试数据的代沟
收缩自编码网络
收缩自编码网络使用特征抽取函数来抵抗输入的微扰。收缩自编码器的鲁棒性体现在对隐藏层的表达上,可以看作是 降噪自编码+稀疏自编码。
堆叠自编码网络
多个自编码器级联,逐层提取特征。得到的特征更有代表性,维度更小。
深度自编码网络
使用预先训练好的层堆栈而成的限制波兹曼机
VAE - Variational Auto Encoder
VAE(变分自编码器)是一种用于生成式模型的神经网络架构。它结合了自编码器和变分推理的思想,可以学习数据的潜在表示并生成新的数据样本。VAE 通过训练一个神经网络来学习一种从高维数据到低维表示的映射,并通过变分推理来估计潜在表示的分布。
VAE 的结构由编码器和解码器两部分组成,但与普通自编码器的不同之处在于 VAE 引入了一个潜在空间,并通过采样和变分推理来学习这个空间的分布。这样,VAE 可以生成新的数据样本,并且能够控制生成样本的特征。
VAE 的损失构成
VAE 的损失函数通常由两部分构成:重构损失和 KL 散度。重构损失用于计算输入数据和重构数据之间的差异,通常使用像均方误差这样的损失函数。KL 散度用于度量潜在表示分布和预定义的正态分布之间的差异。通常,VAE 的损失函数为两部分的线性组合,即重构损失和 KL 散度的加权和。通过最小化这个损失函数,VAE 可以学习到潜在表示的最优分布,并使输入和重构数据之间的差异最小。
KL散度
KL散度(Kullback-Leibler divergence)是衡量两个概率分布之间差异的一种测量方法。它定义为一个概率分布 p 在另一个概率分布 q 的条件下的平均信息量。KL 散度的计算方法为:
GAN
GAN(生成对抗网络)是一种生成式模型,它由两个神经网络组成:生成器和判别器。生成器的目标是生成与真实数据相似的虚假数据,判别器的目标是分辨真实数据和生成器生成的虚假数据。
GAN 通过训练这两个网络来提升它们的能力,使得生成器生成的数据越来越逼真,判别器越来越难以将真实数据和虚假数据区分开来。
GAN 的目标是学习到真实数据的分布,并能生成与真实数据相似的数据。它在计算机视觉领域中得到广泛应用,用于图像生成和图像修复等任务。
GAN 的网络结构
GAN 由两个神经网络组成:生成器和判别器。生成器的网络结构与一般的神经网络类似,包括输入层、隐藏层和输出层。它的输入是随机噪声,通过多层神经网络转换为与真实数据相似的虚假数据。判别器的网络结构也与一般的神经网络类似,它的输入是真实数据或生成器生成的虚假数据,通过多层神经网络进行判别,最终输出一个概率值表示输入数据是否为真实数据。
训练过程
- 生成器从随机噪声中生成虚假数据。
- 判别器对真实数据和虚假数据进行判别,并输出判别结果。
- 根据判别器的输出结果,计算生成器和判别器的损失函数。
- 使用优化器更新生成器和判别器的参数。
- 重复上述过程,直到模型收敛为止。
在 GAN 的训练过程中,生成器和判别器交替更新参数,通过这种博弈的方式来优化模型的性能。
DCGAN
DCGAN(深度卷积生成对抗网络)是一种应用于图像生成的 GAN 模型,它结合了卷积神经网络和生成对抗网络的思想。DCGAN 在生成器和判别器的网络结构中使用了卷积层,使得模型能够学习图像中的空间特征。
DCGAN 还引入了许多技巧来提升模型的性能,例如使用批标准化和 ReLU 激活函数。