人脸检测模型 MTCNN
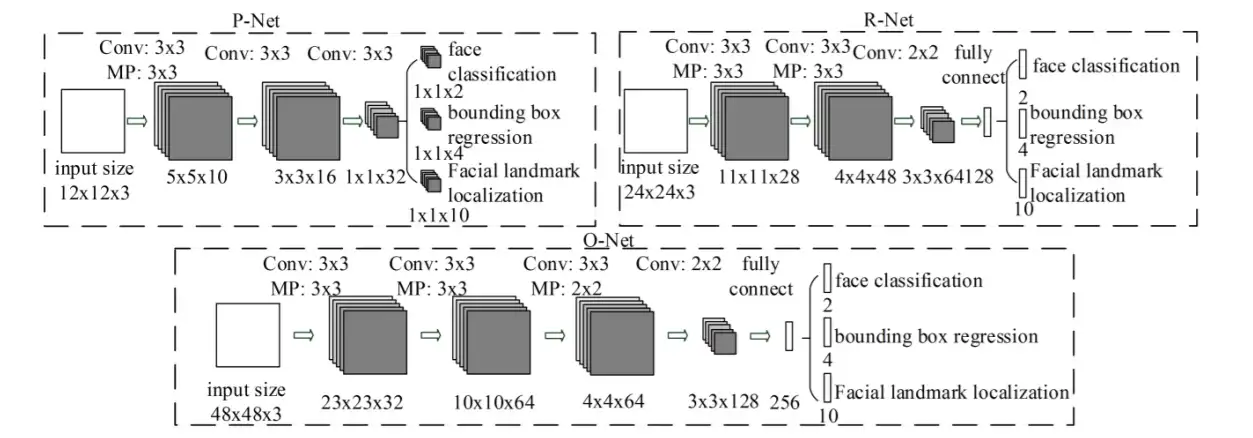
MTCNN (Multi-task Cascaded Convolutional Neural Network) 是一种用于人脸检测的神经网络模型。它是由三个子网络组成的级联模型,每个子网络都被训练来执行特定的任务。
MTCNN 通常在人脸识别、人脸跟踪和人脸验证等应用中使用,因为它能够快速、准确地检测出图像中的人脸。它还可以用于生成人脸轮廓线,这对于进行人脸美颜和脸部特征分析等应用非常有用。
网络结构
- 第一个子网络(P-Net)被训练来生成人脸框和脸部边界框。
- 第二个子网络(R-Net)被训练来精细定位人脸的位置和大小。
- 第三个子网络(O-Net)被训练来生成高质量的人脸框和五个人脸关键点(眼睛、鼻子、嘴巴等)的位置。
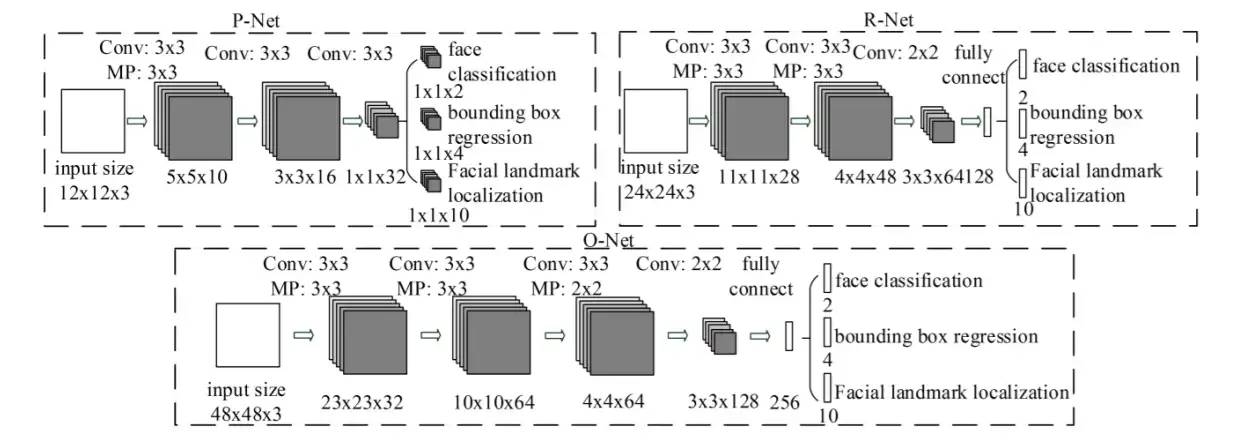
流程
MTCNN 的工作流程大致如下:
- 对输入图像进行缩放,以便在不同尺度下检测人脸。
- 使用第一个子网络(P-Net)生成人脸框和脸部边界框。
- 使用 NMS 算法去除冗余检测框。
- 对剩余的检测框使用第二个子网络(R-Net)进行精细定位。
- 再次使用 NMS 算法去除冗余检测框。
- 对剩余的检测框使用第三个子网络(O-Net)生成高质量的人脸框和五个人脸关键点的位置。
MTCNN 使用偏移量计算人脸位置和大小
MTCNN 中使用偏移量计算的目的是用于精细定位人脸的位置和大小。
在 MTCNN 中,偏移量是指对于每个人脸框,都可以用四个浮点数表示的回归量来调整人脸框的位置和大小。这四个浮点数分别表示人脸框的左上角的水平偏移量、垂直偏移量、宽度偏移量和高度偏移量。
偏移量计算的方法通常是使用回归学习,即使用训练数据来学习一组权重参数,使得这组参数能够最小化预测偏差。回归学习通常使用最小二乘法或梯度下降法来优化参数。
在 MTCNN 中,偏移量计算的目的是将生成的人脸框与真实人脸框尽可能地匹配。这样,在后续的人脸识别、人脸跟踪和人脸验证等应用中,就可以使用较为精确的人脸框来进行处理。
原图坐标反算
设原图像的尺寸为 W 和 H,原图像中人脸框的左上角坐标为 (x1, y1),右下角坐标为 (x2, y2),人脸框的宽度为 w = x2 - x1,高度为 h = y2 - y1。如果在 MTCNN 中得到了四个偏移量 (dx1, dy1, dx2, dy2),则可以使用下列公式计算新的人脸框坐标:
偏移量的值在 -1 到 1 之间,所以新的坐标可能会超出原图像的范围。如果出现这种情况,则需要将新的坐标限制在原图像的范围内。例如,如果 x1' < 0,则应将 x1' 设为 0;如果 x2' > W,则应将 x2' 设为 W。
反过来,如果你已经得到了新的人脸框坐标 (x1', y1', x2', y2'),则可以使用下列公式计算偏移量:
注意,偏移量的值也应该限制在 -1 到 1 之间,以避免出现错误的结果。
IOU (交并比)
在 MTCNN 中,IOU(Intersection over Union)是用来衡量人脸框的准确性的指标。IOU 表示两个人脸框的相交区域占两个人脸框并集的比例。
具体来说,如果有两个人脸框 A 和 B,则 IOU 可以使用以下公式计算:
IOU =
其中 表示两个人脸框的相交区域, 表示两个人脸框的并集。
IOU 的值在 0 到 1 之间,值越大表示两个人脸框的相似度越高。通常,当 IOU 的值大于一个阈值(例如 0.5)时,两个人脸框被认为是重叠的。在 MTCNN 中,可以使用 IOU 来过滤掉不准确的人脸框,从而提高人脸检测的准确性。
NMS (非极大值抑制)
MTCNN 中的 NMS(非极大值抑制)是一种用于去除冗余检测框的方法。
在 MTCNN 中,每个子网络都会生成多个人脸检测框,但是很多检测框可能会重叠或者相似,这就导致了冗余。为了去除这些冗余检测框,MTCNN 使用 NMS 算法。
出现重复框的原因
MTCNN 中预测的结果之所以会出现很多重复框,是因为在检测过程中使用了多尺度检测的方法。
在多尺度检测中,MTCNN 会对输入图像进行缩放,以便在不同尺度下检测人脸。这样一来,对于同一个人脸,MTCNN 就会生成多个检测框,其中有些框可能会重叠。
NMS
NMS 算法的基本思想是,对于每个检测框,计算与其他检测框的重叠率(IoU)。如果某个检测框与其他检测框的重叠率较高,则保留具有较高置信度(confidence score)的检测框,并删除其他检测框。
具体来说,MTCNN 使用下面的步骤进行 NMS:
- 将检测框按照置信度从大到小排序。
- 选取置信度最大的检测框,并将其加入最终结果集。
- 删除与当前检测框重叠率较高的检测框。
- 重复步骤 2 和 3,直到遍历完所有检测框。
NMS 算法的主要目的是去除冗余检测框,以便提高检测效率和准确率。在 MTCNN 中,NMS 算法通常用于第二个子网络(R-Net)和第三个子网络(O-Net),因为这两个子网络往往会生成更多的检测框,而且检测框的质量也更高。
MTCNN 中使用 NMS 算法的参数是重叠率阈值(overlap threshold)。在计算两个检测框的重叠率时,如果重叠率超过了这个阈值,就会将其中较低置信度的检测框删除。通常来说,重叠率阈值设置在 0.7 到 0.9 之间,可以根据具体应用场景进行调整。
另外,在 MTCNN 中,还有一种类似于 NMS 的方法,叫做 Bounding Box Regression(BBR)。BBR 的主要目的是通过回归来精细调整检测框的位置和大小,以便更准确地检测人脸。BBR 通常与 NMS 算法一起使用,能够帮助 MTCNN 更快速、准确地检测出图像中的人脸。
优缺点及改进方法
优点
- MTCNN 使用了级联模型,可以在不同尺度下检测人脸,并且能够适应图像中人脸的不同姿态。
- MTCNN 使用了三个子网络,每个子网络都被训练来执行特定的任务,这样可以保证检测的准确性。
- MTCNN 在人脸识别、人脸跟踪和人脸验证等应用中表现良好,并且在处理较大图像时也具有较好的性能。
缺点
- 检测速度较慢:MTCNN 由三个子网络组成,因此检测速度较慢。
- 对小脸的检测效果不佳:MTCNN 检测小脸时,容易漏检或误检。
- 旋转角度较大的人脸的检测效果不佳:MTCNN 对旋转角度较大的人脸的检测效果不佳。
改进方法
- 使用多尺度检测:MTCNN 使用多尺度检测可以提高对小脸的检测准确率。
- 使用更多的训练数据:丰富的训练数据可以帮助 MTCNN 学习到更多的人脸特征,从而提高对小脸的检测准确率。
- 使用更复杂的网络结构:使用更复杂的网络结构(例如 ResNet、Inception 等)可以帮助 MTCNN 学习到更多的人脸特征,从而提高对小脸的检测准确率。
- 使用旋转不变的卷积层:使用旋转不变的卷积层可以提高对旋转角度较大的人脸的检测准确率。
- 使用更多的人脸关键点:使用更多的人脸关键点可以帮助 MTCNN 学习到更多的人脸特征,从而提高对旋转角度较大的人脸的检测准确率。
- 使用更多的检测框:使用更多的检测框可以提高 MTCNN 的检测准确率,但是也会增加计算复杂度。
- 使用更高分辨率的输入图像:使用更高分辨率的输入图像可以帮助 MTCNN 检测到更多的细节,从而提高检测准确率。但是,这也会增加计算复杂度。
课件
