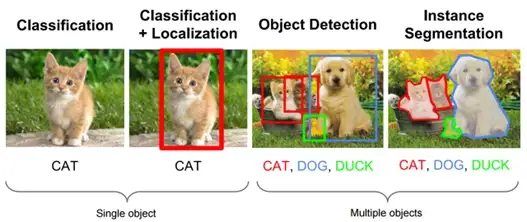
YOLO v1-v5
R-CNN
R-CNN 算法流程
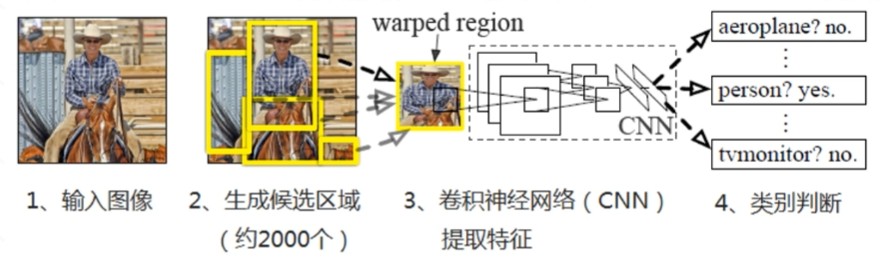
- 输入图像
- 使用 selective search 的传统聚类算法在每张图像上生成 1K ~ 2K 个候选区域
- 对每个候选区域,使用深度网络提取特征 (AlextNet、VGG 等 CNN 都可以)
- 将特征送入每一类的 SVM 分类器 , 判别是否属于该类
- 使用回归器精细修正候选框位置
缺点
- 需要事先提取多个候选区域对应的图像,占用大量磁盘空间,且影响速度
- CNN 需要固定尺寸的输入,缩放图像时会造成图像变形影响精度
- 没有使用 NMS,导致较多重复的特征提取
Selective Search
用于目标检测的区域提议算法。通过图像的视觉结构(如颜色和纹理)将图像分成许多不同的部分,然后枚举这些部分的组合,找到最有可能包含目标的区域。先使用小尺度搜索,再合并特征相似的区域进行大尺度搜索。优点有:
- 能够捕捉不同尺度
- 多样化
- 快速计算
Fast R-CNN
将从原图选出聚类候选框的方法改成了从 CNN 层之后选出的特征图上聚类候选框
ROI-Pooling - 把不同大小的输入映射到一个固定尺度的特征向量。将每个候选区域均匀分成 M×N 块,对每块进行 max-pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
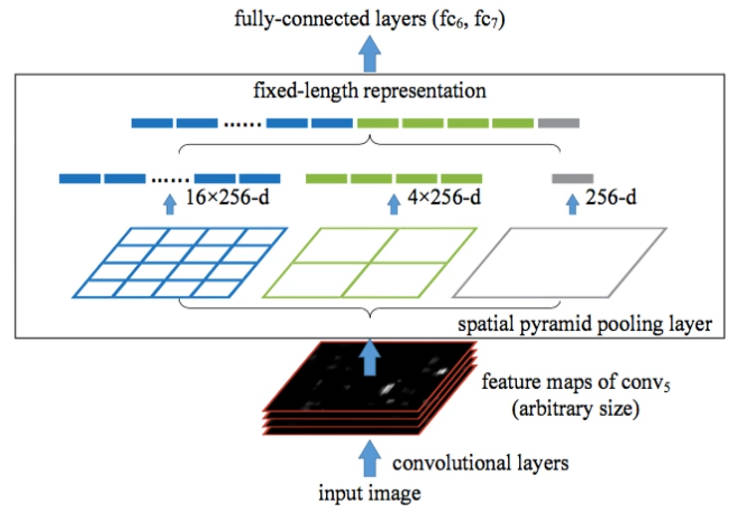
SPP-Net 空间金字塔池化
空间金字塔池化是一种图像降采样技术,常用于视觉识别和特征提取等任务中。基本思想是,将输入图像不断缩小,然后对每个尺度的图像进行特征提取。这样做的优点是:可以在保留图像的重要信息的同时,降低计算量和存储空间的需求;允许任意尺寸的输入,均能产生固定尺寸的输出;提高尺度不变性,减少过拟合。常见的空间金字塔池化方法有最大池化、平均池化和基于拉普拉斯金字塔的池化等。
Faster R-CNN
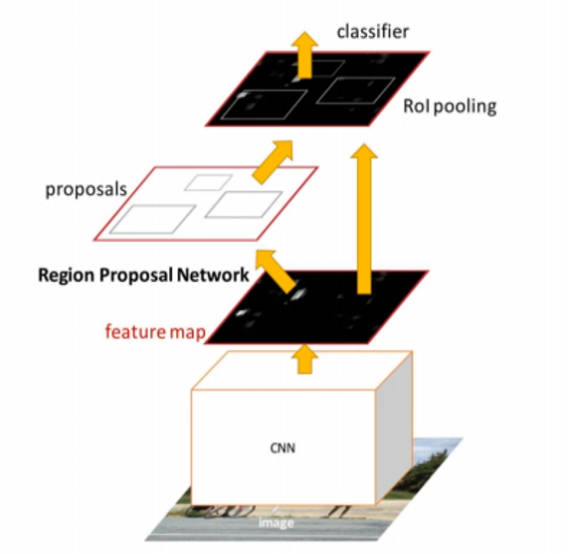
使用区域生成网络 (Region Proposal Network) 代替 Fast R-CNN 中费时的 Selective Search 方法。
RPN (Region Proposal Network)
YOLO-v1 (You Only Look Once)
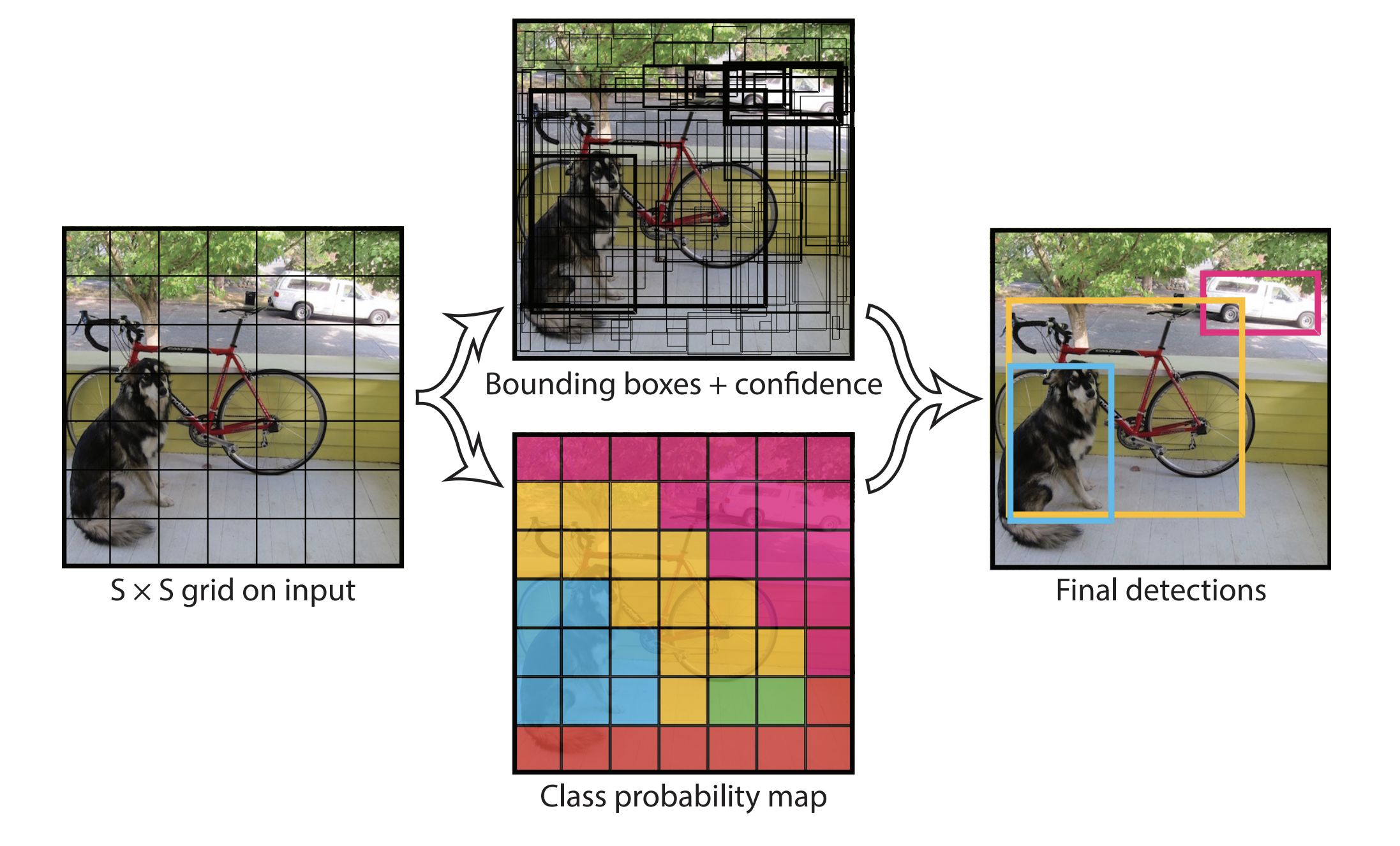
在YOLOv1中,它将整张图片输入后平均分为S×S个网格(grid cell),当某个目标的中心落在这个网格中,那么这个网格就负责预测它。对于 Faster-RCNN 需要训练一个RPN网络获得目标候选框区域,然后再映射到特征图上得到特征矩阵,这消耗了大量时间空间。
- 输入图像分为 S×S 个网格,如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object
- 每个网格要预测 B 个bounding box,每个 bounding box 除了要回归自身的位置和一个值,即 (x, y, w, h) 和 confidence 共5个值。
- 每个网格还要预测一个类别信息,记为 C 类。则SxS个网格,每个网格要预测 B 个 bounding box 还要预测 C 个 categories。总的输出就是 S × S × (5×B+C) 的张量
在 YOLOv1 的 CVPR 2016 论文中,图片输入为 448×448 的像素,S图片划分网格量=7,B每个网格预测边框量=2,C类别个数=20。于是,网格输出=7×7×(5×2+20)
网络结构
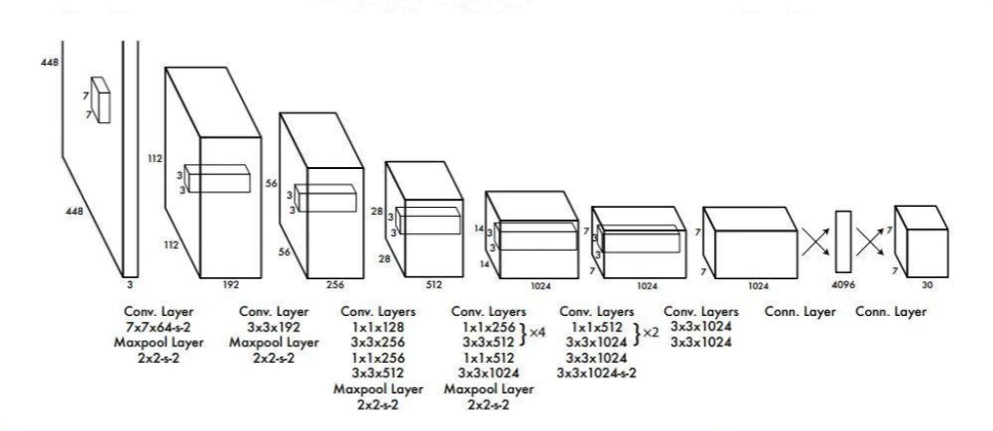
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
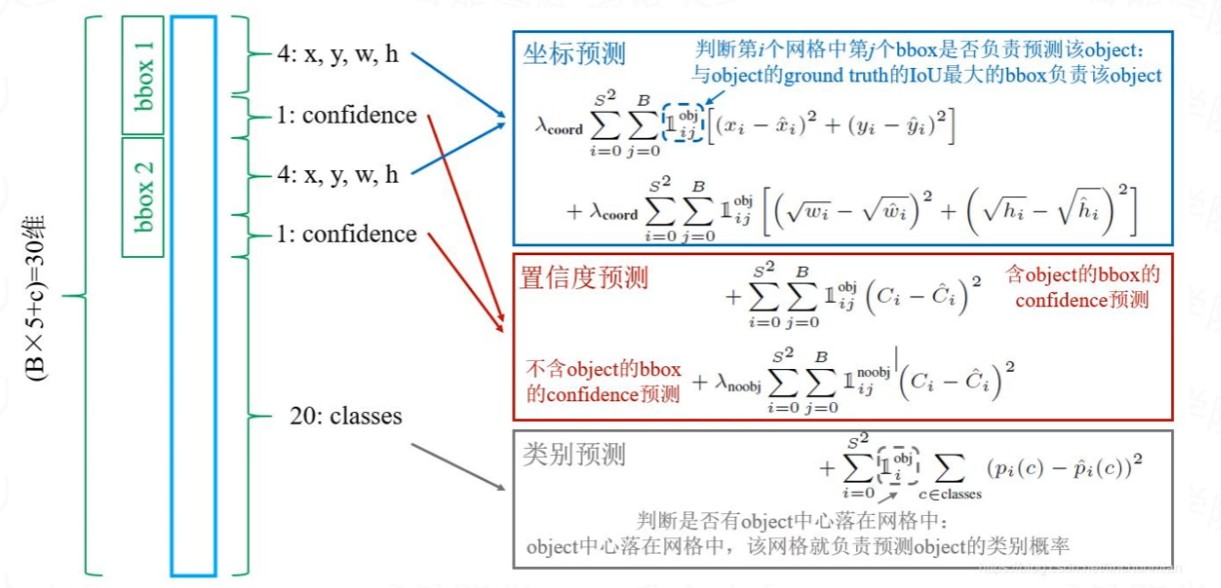
损失函数
YOLO-v2
提升点
- Batch Normalization 简称 BN 层,即批量标准化。在每一层卷积后,都增加了批量标准化进行预处理。BN 层能够对数据进行预处理,完成图像均衡化,解决反向传播的梯度消失/爆炸,去噪等功能,提升训练速度,并且起到一些正则化效果,可以移除 Dropout 层。
- High Resolution Classifier YOLOv2采用更高分辨率的分类器,在采用 224×224 图像进行分类模型预训练后,再采用 448×448 高分辨率样本对分类模型进行微调(10 个 epoch),带来了4% 的 mAP 提升。
- Convolution with Anchor Boxes 通使用基于 Anchor 的目标边界框的预测方式。采用基于 Anchor 偏移的预测比直接预测坐标而言更简单,也能使得网络更加容易学习和收敛。YOLOv2 移除了 YOLOv1 中的全连接层而采用了卷积和 anchor boxes 来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个 pool 层。YOLOv2 使用了 Anchor boxes 之后,每个位置的各个 anchor box 都单独预测一套分类概率值。
YOLOv1:
YOLOv2:
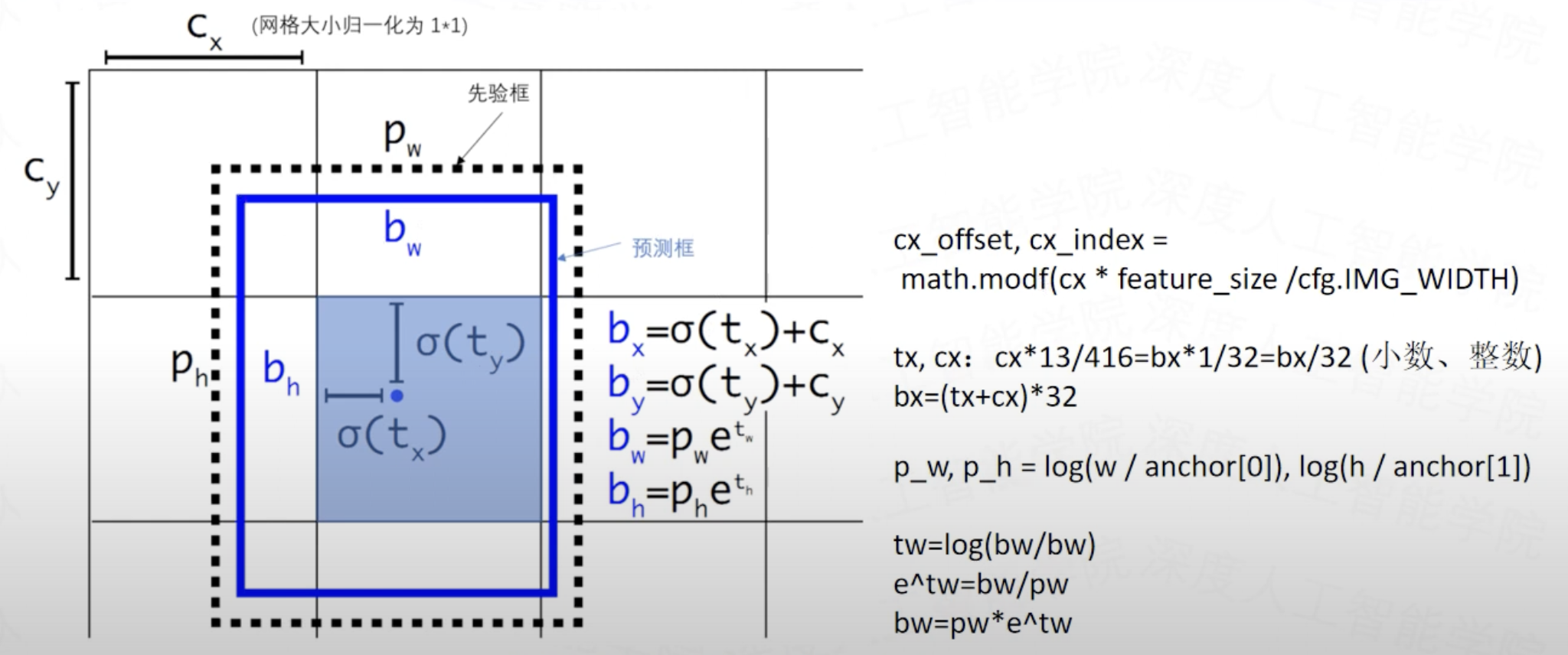
- Dimension Clusters
- Direct location prediction
YOLO 9000
YOLO9000 是在 YOLOv2 的基础上提出的一种可以检测超过 9000 个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。在 YOLO 中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
YOLO-v3
- 更高的检测精度: YOLO v3使用了一种名为"darknet-53"的深度卷积神经网络模型,该模型在保持较快的速度的同时具有更高的检测精度。
- 多尺度预测: YOLO v3使用多尺度预测的方法,可以检测出尺寸不同的目标。
- 强化的边界框回归: YOLO v3在边界框回归方面进行了改进,可以更准确地预测目标的位置。
- 支持不同分辨率的输入图像: YOLO v3可以接受各种分辨率的输入图像,这有助于检测出尺寸不同的目标。
- 快速: YOLO v3在保持较高的检测精度的同时,运行速度较快。
YOLO-v4v5
网络结构对比
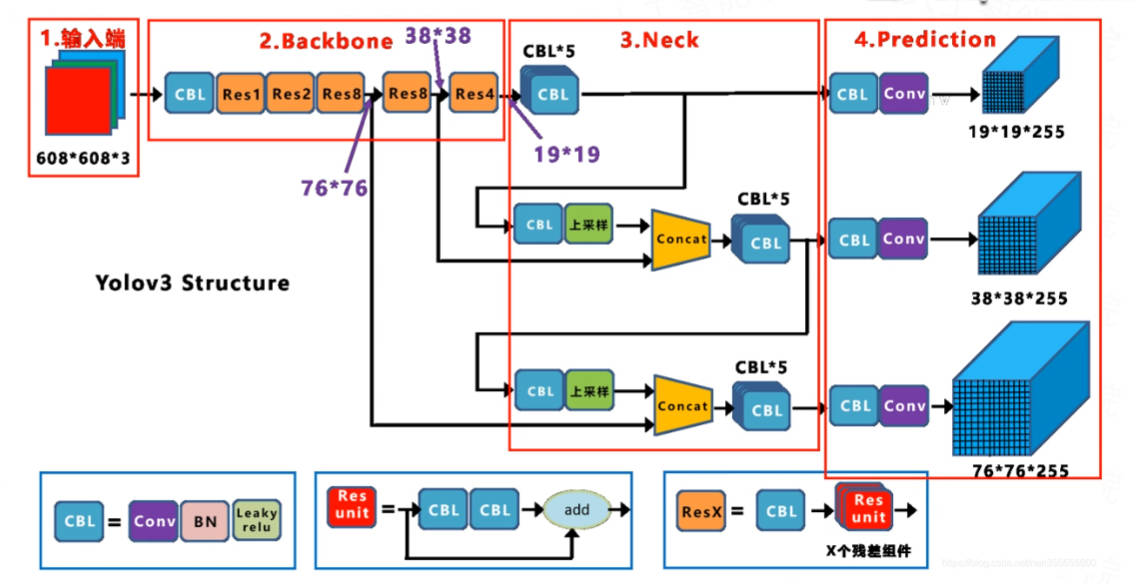
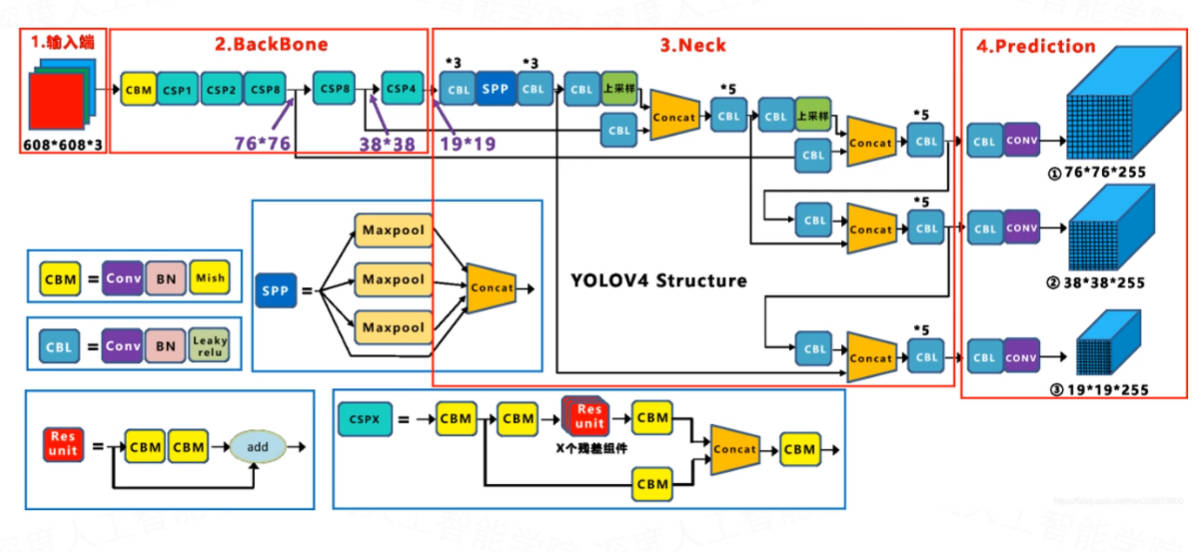
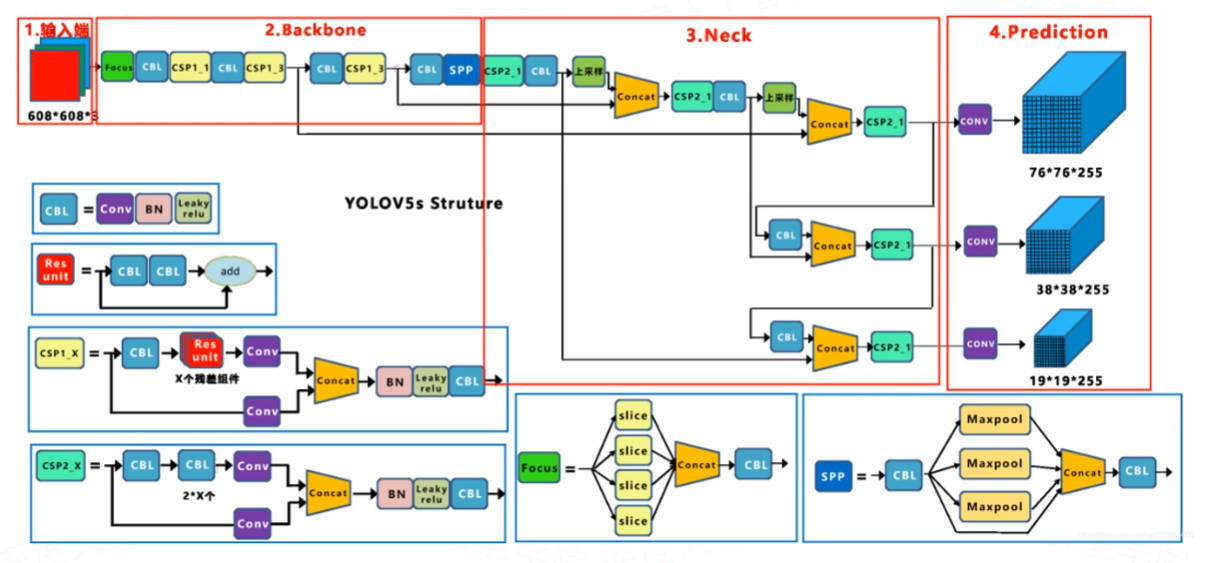
损失设计
GIOU_Loss
GIOU (Generalized Intersection over Union) 在 IoU 的基础上引入了更复杂的几何计算,增加了一个项,这个项考虑了预测边界框和真实边界框的最小闭合矩形的面积。
在这个公式中,第一项是 IoU,第二项则是用最小闭合矩形的面积减去并集面积,然后除以最小闭合矩形的面积。这个额外的项可以在两个边界框没有重叠的情况下,提供有意义的梯度,从而帮助模型学习如何改进预测。
DIOU_Loss
DIOU (Distance-IoU) Loss 是一种用于目标检测任务中的损失函数,它在计算目标框(bounding box)之间的损失时,除了考虑传统的 IOU(Intersection over Union,交并比)之外,还加入了中心点距离的考量。
其中,ρ 是预测框和真实框中心点的欧氏距离,c 是包含两个框的最小闭合矩形的对角线长度。这样,当两个框的中心点距离变小,DIOU 的值会增大,表示两个框的相似度更高。反之,当中心点距离变大,DIOU 的值会变小,表示两个框的相似度更低。
CIOU_Loss
Complete Intersection over Union Loss
- 形状差异:CIOU Loss 计算了预测框和真实框之间的形状差异。即使两个框的 IOU 相同,形状差异的存在也可能导致检测的准确性降低。
- 中心点距离:CIOU Loss 还会考虑预测框和真实框中心点之间的距离。如果两个框的中心点距离较远,即使它们的 IOU 较高,也可能导致检测结果的准确性降低。
- 面积比例:CIOU Loss 还考虑了预测框和真实框的面积比例。如果预测框和真实框的面积比例偏差较大,可能导致检测结果的准确性降低。
数据增强
几何变换
- 随机缩放
- 裁剪
- 翻转
- 旋转
- 平移
光照变换
- 随机亮度
- 对比度
- 色彩度
- 饱和度
- 噪声
遮挡变换
- Random erase 随机删除 , 在图上随机遮挡某一部分的像素 。
- Cutout 裁剪 , 按照一定的间隔遮挡 N × N 像素大小的小格子,是具有规律的,一般是等距间隔的小格子,N 一般取2或4很小的值,类似于给图片加噪声。
- Hide and seek 裁剪,按照更大的间隔遮挡 N × N 像素大小的小格子,是具有规律的,一般是等距间隔的小格子,N 一般取值更大一些。
- Grid Mask 网格掩码,YOLOV4 中的遮挡是有策略的遮挡,而非随机遮挡,采用的方法是先把图像进行分成不同的格子,然后按照一定的方法去挑选遮挡某些格子,尽量不去遮挡目标。遮挡的效果取决于格
子的大小和被遮挡的格子数量。类似于增加正样本的权重 (YOLO 图像中一般背景面积较大)。
课件
YOLO v1v2v3

YOLO v4v5
